If you’re seeking an employment opportunity for a software engineering-related job interview then you must learn the decision tree. Decision tree interview questions are a popular topic for a job seeker preparing for software engineer or web developer interviews. The decision tree algorithm solves many problems in computer programming, so interviewers like to ask questions to test a candidate’s understanding of the algorithm.
Decision Tree Interview Questions
Below are a few of the most frequently-asked questions about decision tree. We’ll also share a few Python code examples to illustrate key concepts.
What is a decision tree?
Decision trees are a machine learning algorithm that can be utilized to solve classification and regression issues. It is simple to learn and use. You can apply the condition at each node to perform further action, and this flow continues until the last nodes. In the following diagram, you can see a decision tree regarding a bank loan and you have different decision nodes and each node has its conditions.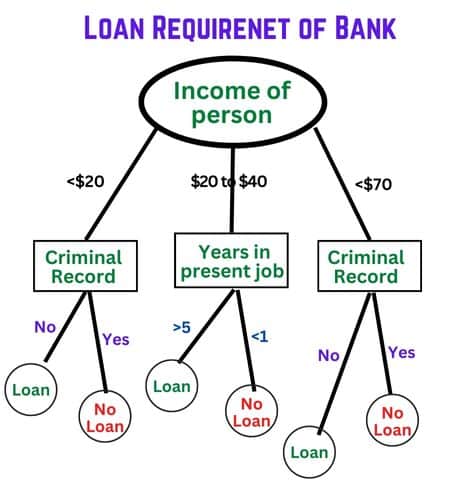
How does the decision tree algorithm work?
The algorithm divides the information into small segments known as nodes. Each node is an important decision that must be taken. The algorithm then looks at each group’s data and decides which group to split next. The process continues until all data has been split into groups as uniform as they can be.
What is Entropy in a decision tree algorithm?
Entropy is a measure of the impurity of a group of data. The decision tree algorithm uses Entropy to decide which group to split next. The entropy of a group is calculated by looking at the proportion of data points that belong to each class. It refers to data that lacks order or predictability. High-order data with a high degree of disorder could also be described as having high Entropy. However, data with homogenous data (or pure data) can be considered data with low Entropy.
What is a pure data segment?
The Entropy value is an indication of the integrity of a particular data segment. A data segment is considered pure if its entropy value is close to zero. This means data belongs to one or most of one class level (the one with a label). A value close to 1 indicates maximum disorder or maximum splitting. A pure data segment is a decision tree node that contains only data points that belong to the same class. A node is considered pure if all the data points in the node belong to the same class.
How do you calculate the Entropy of data?
You can calculate the value of Entropy for a data segment by adding n classes to the following formula. p is the probability of an event occurring in class1.
-p * log2 (p)
An Entropy for a segment with the data being part of two categories:
-(0.3)*log2 (0.3) - (0.7)*log2 (0.7)
= – (-0.5211) – (-0.3602)
= 0.8813
Define the types of nodes used in the decision trees.
There are three types of nodes in decision trees: Root nodes, decision nodes, and Leaf nodes
- Root Nodes: The root node is the first node in the decision tree. It represents the entire dataset.
- Decision Nodes: Decision nodes are the nodes that follow the root node. They represent the decision that needs to execute in the next step. Many decision nodes allow data to divide into multiple data segments.
- Leaf Nodes: Leaf nodes are the nodes that represent the final decision. They are the decision points for the decision tree.
What is a leaf node?
A leaf node is a decision tree that has no children. Using the leaf node, you can create predictions by studying the node’s associated data segment.
For example, if we have a decision tree that predicts whether a person is male or female, the leaf nodes would be the final decision for each person. If the decision tree predicts that a person is male, then the leaf node would be male. If the decision tree predicts that a person is female, then the leaf node would be female.
What are Divide and Conquer?
Divide and Conquer can be described as an approach to solving challenges by breaking them down into smaller subproblems. This technique is used to solve both regression and decision tree problems.
What is Gini Impurity?
Gini impurity is a measure of how pure a data segment is. It decides which group to split next. It is determined by looking at the proportion of data points that belong to each class. This is the measurement of disorder in the part of the data. The higher the Gini impurity, the more disorder in the data segment.
How do you calculate Gini impurity?
Gini impurity is calculated by adding up the squares of the probabilities of each class.
Gini Impurity = 1 – (p1^2 + p2^2 + … + pn^2)
where pi is the probability of class i.
For example, if there are two classes, A and B, and the probability of class A is 0.3, and the probability of class B is 0.7, the Gini impurity will be:
Gini-Impurity = 1 – (0.3^2 + 0.7^2)
. = 1 – (0.09 + 0.49)
= 0.42
What is information gain?
Information gain measures how much disorder is reduced by splitting a data segment. It is used to decide which group to split next. The more information you gain, the more disorder decreases.

Source: https://en.wikipedia.org/wiki/Decision_tree_learning
Explain Pre-pruning vs Post-pruning decision tree.
Pre-pruning Decision Tree
Pre-pruning decision trees stop the tree from growing further when they reach a certain level of purity. You can do it by setting a limit on the depth of tree or the number of leaves in the tree. Pre-pruning is more effective than post-pruning because it prevents the tree from overfitting the data.
Post-pruning decision trees
Post-pruning decision trees allow the tree to grow to its full potential and then prune it by removing certain nodes. You can do it by setting a threshold on the information gained. Post-pruning is less effective than pre-pruning because it can lead to overfitting.
What is the CART Algorithm?
The CART stands for Classification & Regression Trees and is a greedy algorithm. It looks for an optimal split at the highest level and is then repeated on all levels.
It also checks whether the split will result in the lowest impurity. Although the solution provided to the greedy algorithm may not be optimal, it can often produce a reasonably good solution.Finding the best trees is an extremely difficult task that has an exponential complexity. This makes the task much more difficult for small training groups. We must choose a “reasonably great” solution over an ideal one.
What are the benefits of using a decision tree?
There are several benefits of using a decision tree:
- It is simple to learn and understand.
- It is a versatile algorithm, and you can utilize it to solve classification and regression issues.
- It is also resistant to overfitting.
- It can deal with both numerical and categorical data.
What are the drawbacks of using a decision tree?
There are several drawbacks to using a decision tree:
- Overfitting: decision trees can easily overfit the data if the tree is not pruned properly.
- High variance: decision trees can have high variance if the data is not split evenly.
- Not scalable: decision trees are not scalable and cannot handle large datasets.
What is a decision stump?
The term “decision stump” refers to a tree that is single-level. It is used to make predictions by looking at a single feature.
For example, if we want to predict whether a person is male or female, we can use a decision stump that looks at the person’s height. If the person is taller than a certain height, we predict that the person is male. If the person is shorter than that height, we expect that the person is female.
Decision stumps are much simpler and easier to train than decision trees but are also less accurate.
How do avoid an Overfitted Decision Tree?
The Pruning technique is a way to reduce the complexity of an overfitted decision tree. It involves deleting child nodes from a branch node and changing the model accordingly.
You can prune in:
- Bottom-up fashion: Begin at the lowest node and work upwards to determine each node’s relevance. The node not relevant to the classification is removed or replaced with a Leaf.
- Top-down fashion: This starts at the root. You can perform a relevance check to determine if a node is relevant for classification. This allows you to drop an entire sub-tree, regardless of its relevance.
Another popular pruning method is reduced error pruning. This involves starting at the and replacing each node with its most populous class.
What is the greedy Greedy Splitting algorithm?
A greedy algorithm is a method of solving a problem using the best available option. The algorithm doesn’t care if the best current result will lead to the ultimate optimal development. Even if the decision is wrong, the algorithm will not reverse it.
Conclusion:
Decision tree models are popular and powerful machine-learning techniques. They are simple to comprehend and use. They are suitable to solve classification and regression problems. However, decision trees can be susceptible to overfitting and are not scalable or can handle large datasets. Pruning is a way to avoid overfitting, and decision stumps are a more robust version of decision trees. Leaf nodes make predictions by looking at the data associated with that node.
While preparing for interview, it is also a good idea to know how to avoid overfitting and understand the different types of decision trees. With this knowledge, you can impress your interviewer and land the job you want.
Thank you.!